
For an Oracle consultant like myself with many years of experience building data warehouses and analytics solutions using the Oracle technology stack, I was naturally skeptical when I was asked to migrate an existing Oracle solution to Snowflake. Just like with any new technology, switching to Snowflake was a learning experience at first. But not to worry, I became a fan of Snowflake soon enough. There are so many cool features in Snowflake, some of them better than in Oracle, that it wasn’t difficult to make the switch to Snowflake.
I’m thrilled with the ease of use of everything in Snowflake. All you have to do is to create an account and you are ready to go. There is no installation, no configuration, no figuring out how to get started as there is a web user interface ready and waiting for you when you sign up for your account. The SQL syntax in Snowflake is similar enough to Oracle that I was productive starting from day one of the migration.
Of course, just like with any new technology, there is a learning curve and it takes time for someone to become proficient, to understand what goes on behind the scenes so that smart design choices can be made, and that new features can be used on a day to day basis without having to think about them or look them up in the documentation.
Summarized in this post, in no particular order of importance, are some of my favorite SQL features in Snowflake that I have started using all the time and that were my pet peeves previously when I was working with Oracle on a regular basis.
QUALIFY
In writing queries for data warehousing, we often rank records according to some criteria and choose the first one or the last one, for example when there are several changes of the record within a time period, we might consider only the last change. This type of query is usually done using the RANK() analytical function. In Oracle, when we want to filter the rank, we have to write a nested select statement, something like this:
SELECT CUSTOMER_ID, CUSTOMER_STATUS FROM (
SELECT CUSTOMER_ID,
CUSTOMER_STATUS,
RANK() OVER (PARTITION BY CUSTOMER_ID ORDER BY CHANGE_DATE DESC) AS STATUS_RANK
FROM CUSTOMER
) WHERE STATUS_RANK = 1;
In Snowflake, we can use the QUALIFY keyword to filter the RANK() analytical function in the same select statement where we calculate it:
SELECT CUSTOMER_ID, CUSTOMER_STATUS FROM CUSTOMER QUALIFY RANK() OVER (PARTITION BY CUSTOMER_ID ORDER BY CHANGE_DATE DESC) = 1;
The code becomes more concise, easier to understand and easier to maintain.
TRY data conversion
When working with messy data that comes into data warehouses, there are often situations where data that should be in date format is not always stored in date format or numbers that should be numbers are sometimes stored with characters other than numeric. There have been countless times in the past when working with Oracle that I spent a significant amount of time searching for invalid dates in huge datasets using SQL when a few records violated the expected data type and the entire query failed. Oracle has added functionality in recent versions that allow error handling during data type conversion, but this was not always the case.
Snowflake has out of the box functionality with built-in functions such as TRY_TO_DATE and TRY_TO_DECIMAL and similar. Instead of using the function TO_DATE, we can simply use TRY_TO_DATE and it will not fail the query when some records don’t match the data type, it will just return null. It is then also easy to identify records where the date format is violated, we just look for columns where the original value is not null and the TRY_TO_DATE function returns null.
Explain query execution plan
Snowflake has a web user interface where a user can view the query execution plan for a particular SQL query as a neatly drawn interactive diagram. For example this query execution plan for the query from the QUALIFY example from earlier:
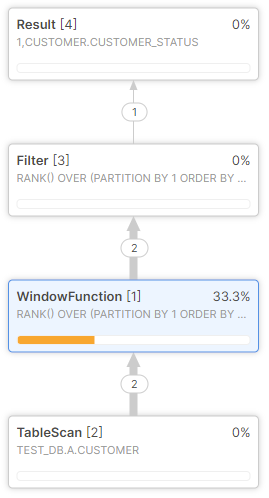
We can see clearly which steps were taken in what order, and which were the most expensive nodes. Sometimes it is inconvenient to click through the user interface or we may be using tools other than the web user interface to work with Snowflake. In such cases it may be more efficient to use an explain plan type of command, similar as in Oracle. Snowflake has us covered with the EXPLAIN command, like this:
EXPLAIN USING TABULAR SELECT CUSTOMER_ID, CUSTOMER_STATUS FROM CUSTOMER QUALIFY RANK() OVER (PARTITION BY CUSTOMER_ID ORDER BY CHANGE_DATE DESC) = 1;
Snowflake displays the explain plan that looks something like this:

In the output we see all the steps with their details that we can review and analyze as needed.
Another cool feature in Snowflake is that we can take the results of a statement such as explain or any other similar type of command such as SHOW or DESCRIBE and so on, and store them in a table for future use or for additional analyses. This brings us to the next item on the list, RESULT_SCAN.
The RESULT_SCAN command returns the result set of a previous command as if the result was a table, for example we can create a temporary table from the previous command, like this:
CREATE TEMPORARY TABLE EXPLAIN_PLAN_OUTPUT AS SELECT * FROM TABLE(RESULT_SCAN(LAST_QUERY_ID()));
This allows us to conveniently store whatever was returned by the last command as a table for further processing or analyses.
There are many more cool features in Snowflake SQL that have grown on me since I have started using them and I’m sure more will be added to my repertoire in future.
For a more in-depth review of the differences between Oracle and Snowflake features, I have written several blog posts for my employer’s website and recorded a webinar, available here: